ANTLR Tutorial
COSC 059 - Principles of Programming Languages
notes
Two major-ish changes in ANTLR4, update from ANTLR3:
- ANTLR4 accepts nearly any grammar you throw at it, even with left-recursion. (trivia: this version is named honey badger)
- Discourages the use of actions directly within grammar. Instead, use listeners and visitors.
See link for details on installing and setting up ANTLR4 in IntelliJ.
arithmetic expressions grammar
grammar for simplified arithmetic expressions
\[\begin{array}{rcl} \gnonterm{prog} & \rightarrow{} & \gnonterm{stat}*\ \gterm{EOF} \\ \gnonterm{stat} & \rightarrow{} & \gnonterm{expr}\ \gterm{NEWLINE} \\ & | & \gterm{ID}\ \gliteral{=}\ \gnonterm{expr}\ \gterm{NEWLINE} \\ & | & \gterm{NEWLINE} \\ \gnonterm{expr} & \rightarrow{} & \gnonterm{multExpr}\ ((\gliteral{+}\ |\ \gliteral{-})\ \gnonterm{multExpr})* \\ \gnonterm{multExpr} & \rightarrow{} & \gnonterm{atom}\ (\gliteral{*}\ \gnonterm{atom})* \\ \gnonterm{atom} & \rightarrow{} & \gterm{INT}\ |\ \gterm{ID}\ |\ \gliteral{(}\ \gnonterm{expr}\ \gliteral{)} \\ \gterm{ID} & \rightarrow{} & (\gliteral{a}\ |\ \gliteral{b}\ |\ ...\ |\ \gliteral{z}\ |\ \gliteral{A}\ |\ ...\ |\ \gliteral{Z})+ \\ \gterm{INT} & \rightarrow{} & (\gliteral{0}\ |\ ...\ |\ \gliteral{9})+ \\ \gterm{NEWLINE} & \rightarrow{} & \gliteral{\r}?\ \gliteral{\n} \\ \gterm{WS} & \rightarrow{} & (\gliteral{ }\ |\ \gliteral{\t})+\ \ \gcmd{/* skip */} \\ \end{array}\]
arithmetic expressions grammar
antlr grammar for simplified arithmetic expressions
grammar Expr; // note: must be same as filename (Expr.g4)
prog : stat+ EOF;
stat : expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr : multExpr (('+' | '-') multExpr)* ;
multExpr : atom ('*' atom)* ;
atom : INT
| ID
| '(' expr ')'
;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE : '\r'? '\n' ;
WS : [ \t]+ -> skip ; // tells ANTLR to ignore these
Antlr plugin for intellij
Antlr plugin for intellij
Antlr plugin for intellij
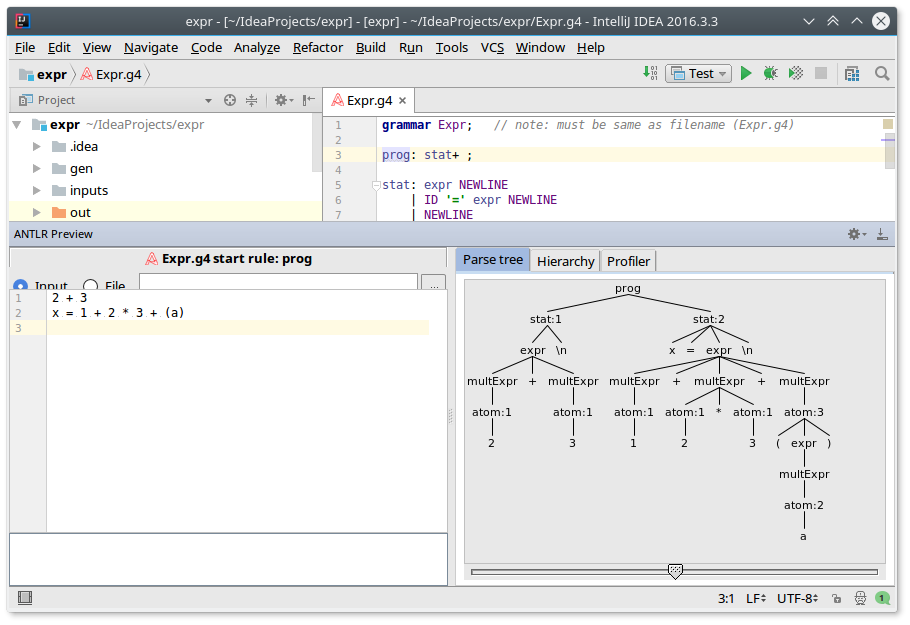
Antlr plugin for intellij
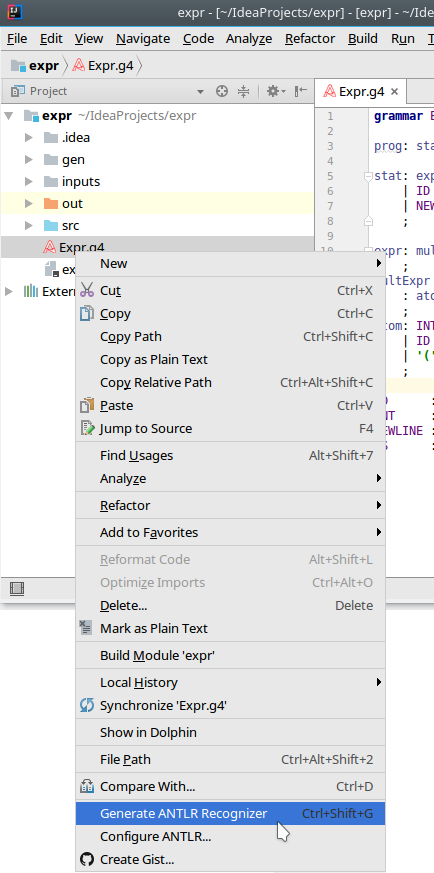
ANTLR can turn your grammar file into Java lexer and parser (with additional machinery) by simply right-clicking on the Expr.g4 file and clicking on Generate ANTLR Recognizer.
Antlr plugin for intellij
ANTLR plugin for IntelliJ generates the following files in the gen/ folder:
Expr.tokens(ExprLexer.tokens)ExprLexer.java,ExprParser.javaExprListener.java,ExprVisitor.javaExprBaseListener.java,ExprBaseVisitor.java
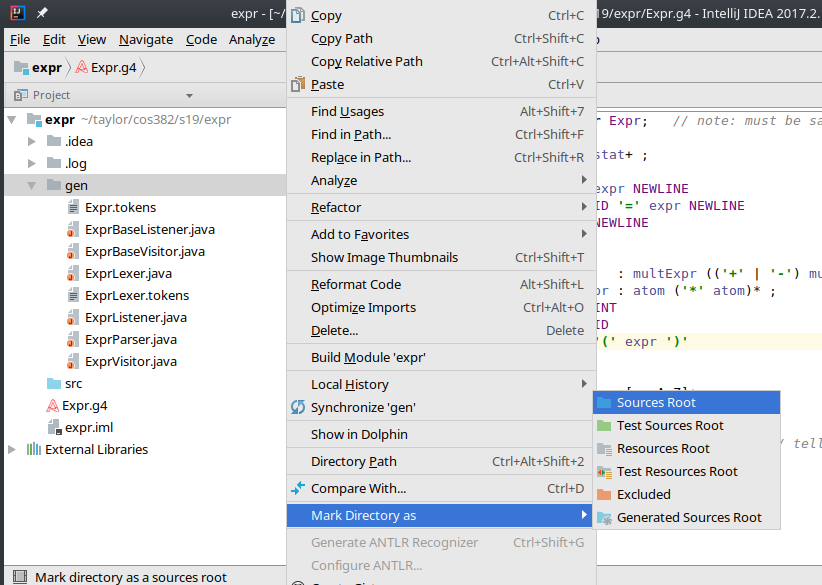
These files are not considered source to IntelliJ, though.
Either move the Java files to the src/ folder or mark the gen/ folder a Sources Root.
Antlr plugin for intellij
exprparser.java psuedocode
prog: stat+ ;
public class ExprParser extends DebugParser {
public final void prog() throws RecognitionException {
// ^^^^ - start symbol!
try {
do {
stat();
} while(/*...*/);
} catch(RecognitionException re) {
reportError(re);
recover(input, re);
}
}
}
Note: Java has been simplified for presentation
exprparser.java psuedocode
multExpr: atom ('*' atom)* ;
public class ExprParser extends DebugParser {
void multExpr() {
try {
atom();
while (next symbol is "*") {
match('*');
atom();
}
} catch (RecognitionException re) {
reportError(re);
recover(input, re);
}
}
}
Note: Java has been simplified for presentation
test program
A simple test program
import org.antlr.v4.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
CharStream input = CharStreams.fromFileName("inputs/test.txt");
ExprLexer lexer = new ExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokens);
parser.prog(); // parse the input stream!
};
}
test file
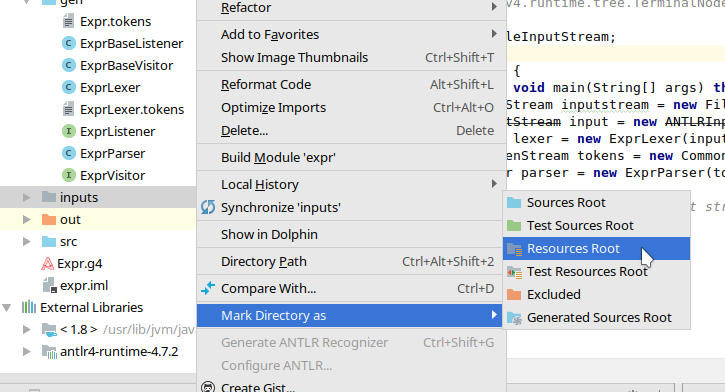
Create a folder in your IntelliJ program called inputs, and then create a file in it called test.txt.
Mark the inputs folder as Resources Root
2 + 3 x = 1 + 2 * 3 + (a)
evaluating the expression
The parser builds a token stream from the input and checks the syntax based on the supplied grammar.
To create a translator or interpreter from the recognizer, the meaning of the valid token stream must be expressed.
Two approaches:
- Use ANTLR Listener
- Use ANTLR Visitor
listener vs visitor
- Listener
- interface that responds to events triggered by the built-in tree walker. Callbacks are called when rules are entered (pre-order traversal) or exited (post-order) while traversal the entire tree.
- Visitor
- interface that allows tree walking to be controlled.
Children in tree are visited by explicitly calling
visitmethod.
The Language Implementation Patterns and The Definitive ANTLR4 Reference books talk about implementing listeners and visitors.
calculator example
Here is an ANTLR4 example of a calculator on GitHub.
https://github.com/shmatov/antlr4-calculator
In this example, the input is parsed, and then a "visitor" will traverse the parse tree to evaluate the expressions.