
Stereo Introduction
COS 351 - Computer Vision

review
In previous section:
- Feature detection and matching
- keypoint detection (find repeatable and distinctive)
- local descriptors
- correspondence
- Model fitting and outlier rejection
- optimization
- Hough transform
- RANSAC
multiple views
This section: multiple views
- Today: intro and stereo
- Next: Camera calibration
- Then: Fundamental matrix
multiple views
- stereo vision
- structure from motion
- optical flow

multiple views: why?
Structure and depth are inherently ambiguous from single views


multiple views: why?
Structure and depth are inherently ambiguous from single views
Cues
What cues help us to perceive 3D shape and depth??
cues: shading
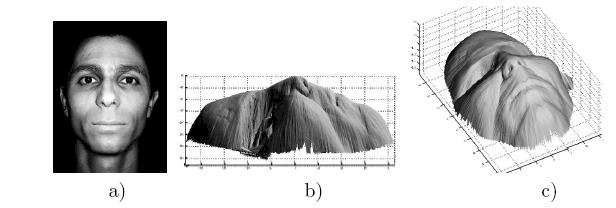
cues: focus/defocus
Images from same point of view, different camera parameters

3D shape / depth estimates
cues: texture


cues: perspective effects

cues: motion




cues: occlusion

If stereo were critical for depth perception, navigation, recognition, etc., then this would be a problem

multi-view geometry problems
Structure: given projections of the same 3D point in two or more images, compute the 3D coordinates of that point
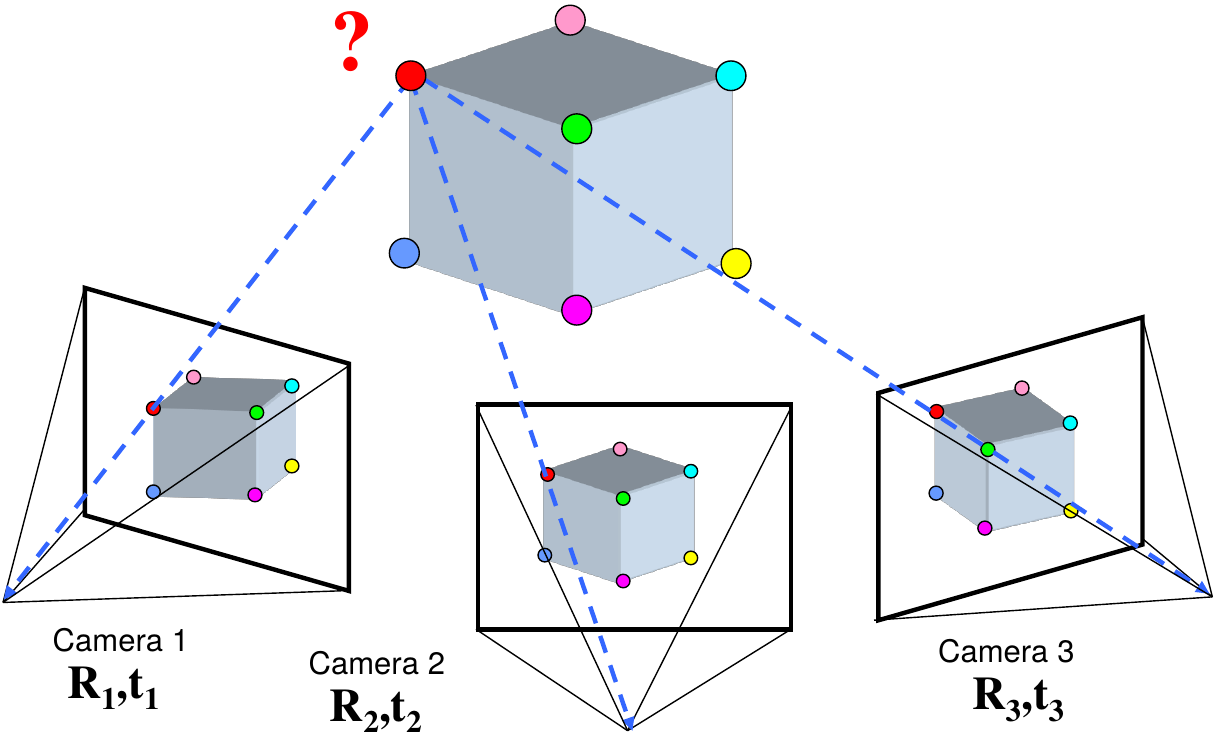
multi-view geometry problems
Stereo correspondence: given a point in one of the images, where could its corresponding points be in the other images?
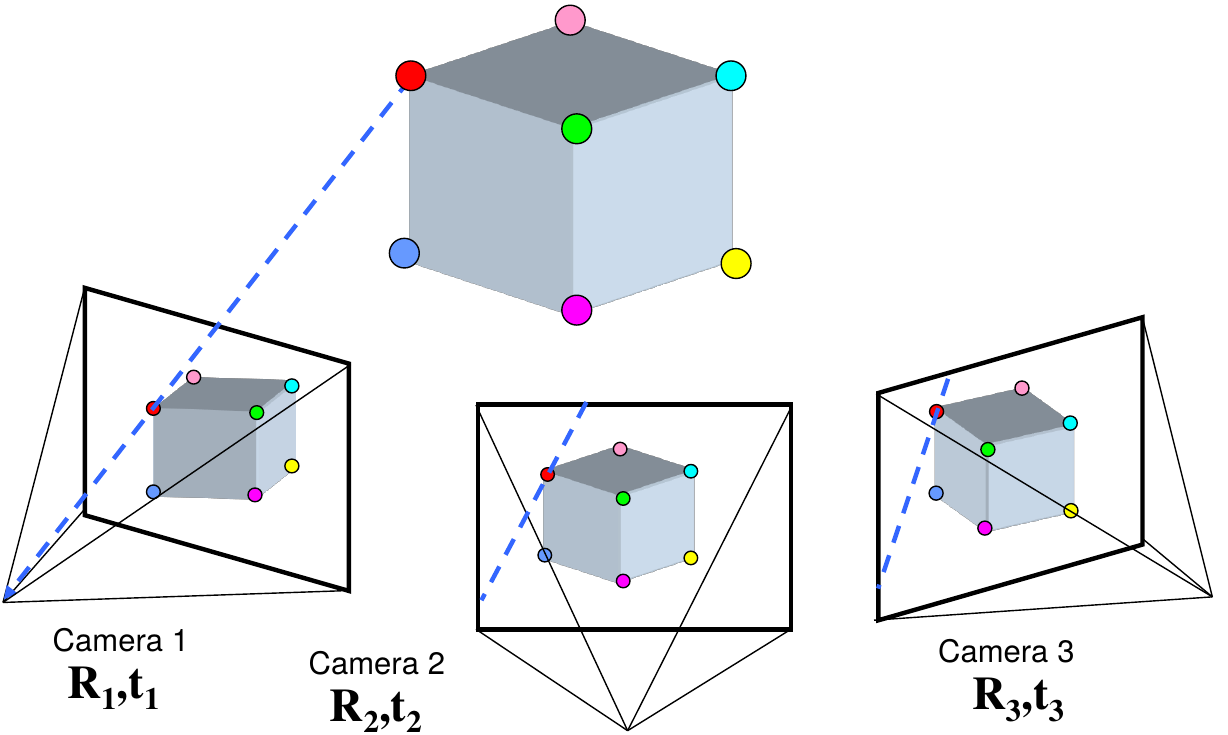
multi-view geometry problems
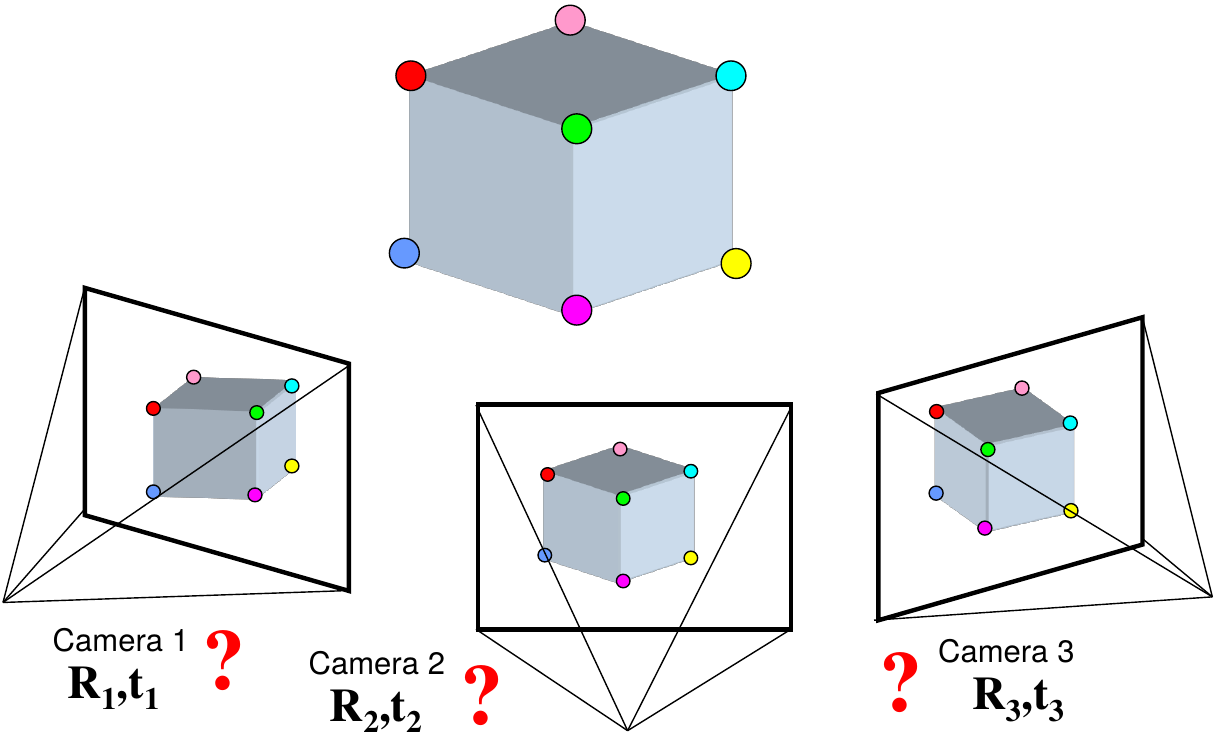
Motion: given a set of corresponding points in two or more images, compute the camera parameters
human eye
Rough analogy with human visual system:
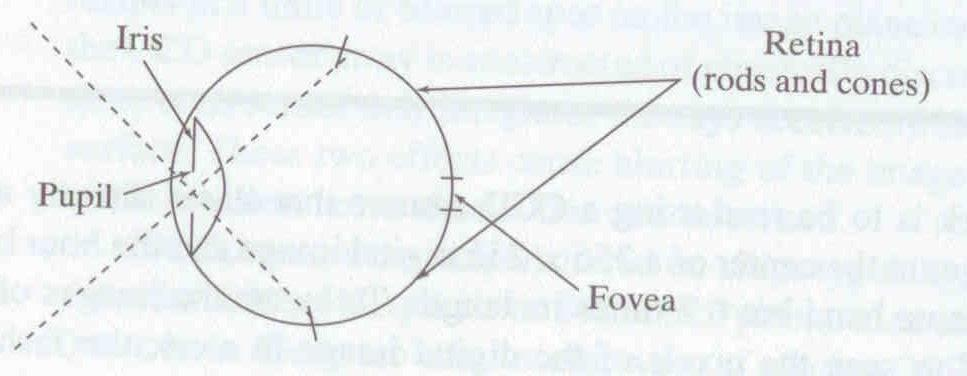
Pupil/iris: control amount of light passing through lens
Retina: contains sensor cells, where image is formed
Fovea: highest concentration of cones
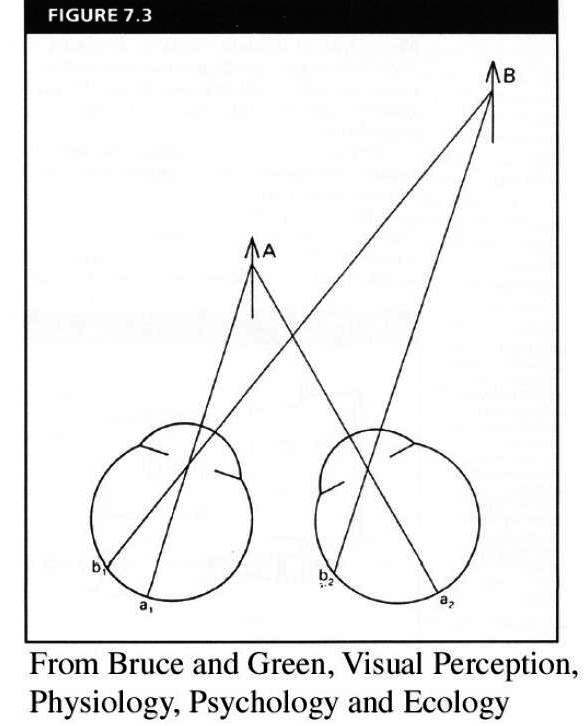
human stereopsis: disparity
Human eyes fixate on point in space: rotate so that corresponding images form in centers of fovea
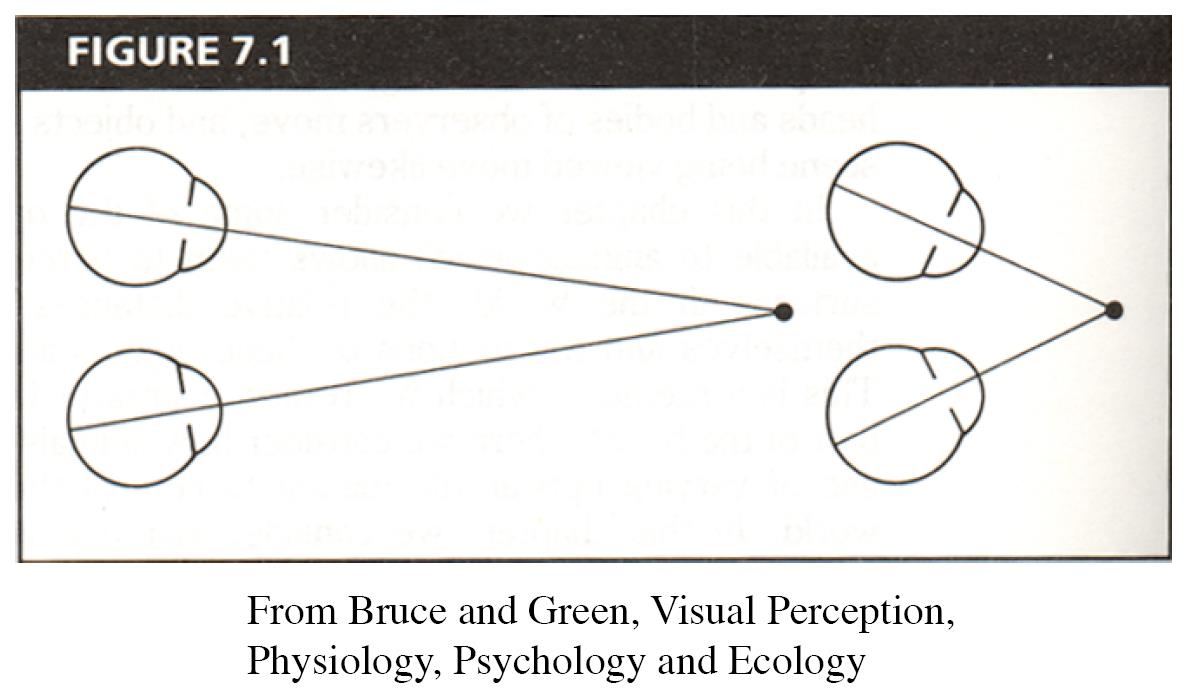
human stereopsis: disparity
Disparity occurs when eyes fixate on one object; others appear at different visual angles
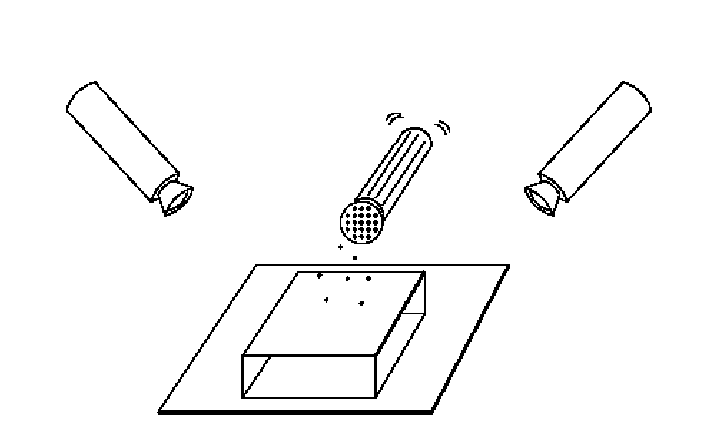
random dot stereograms

Béla Julesz 1960: Do we identify local brightness patterns before fusion (monocular process) or after (binocular)?
To test, pair of synthetic images obtained by randomly spraying block dots on white objects
random dot stereograms
random dot stereograms
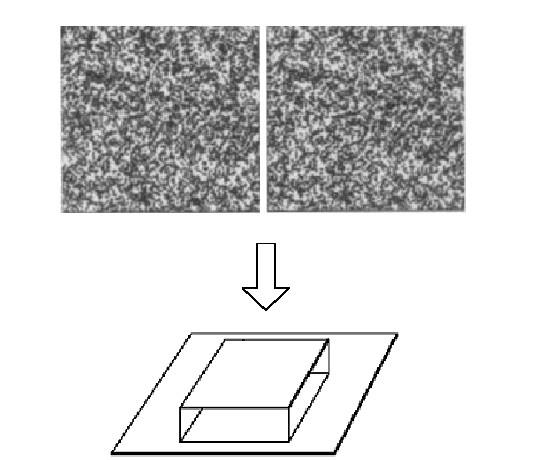
random dot stereograms
- When viewed monocularly, they appear random; when viewed stereoscopically, see 3D structure.
- Human binocular fusion not directly associated with the physical retinas; must involve the central nervous system (V2, for instance)
- Imaginary "cyclopean retina" that combines the left and right image stimuli as a single unit
- High level scene understanding not required for stereo
- But, high level scene understanding is arguably better than stereo
stereo photography and stereo viewers
Take two pictures of the same subject from two slightly different viewpoints and display so that each eye sees only one of the images
Invented by Sir Charles Wheatstone, 1838








autostereograms
Autostereograms exploit disparity as depth cue using single image. (single image random dot stereogram, single image stereogram)

estimating depth with stereo
Stereo: shape from "motion" between two views
We'll need to consider:
- Info on camera pose ("calibration")
- Image point correspondences
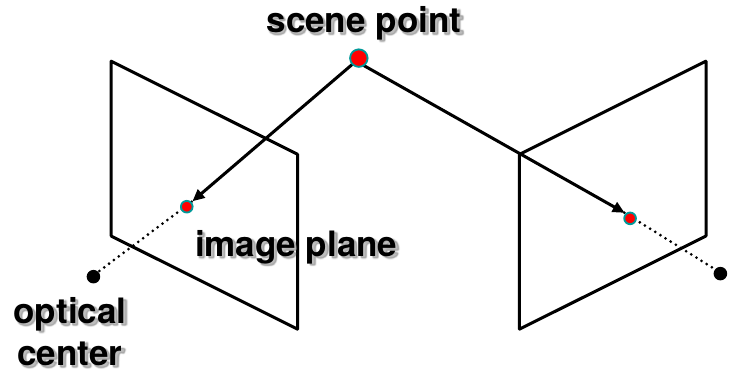

stereo vision





camera parameters
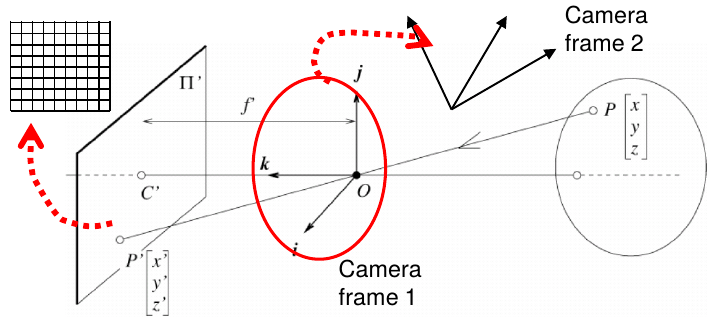
Extrinsic parameters: camera frame 1 \(\leftrightarrow\) camera frame 2
- rotation matrix, translation vector
Intrinsic parameters: image coordinates relative to camera \(\leftrightarrow\) pixel coordinates
- focal length, pixels sizes (mm), image center point, radial distortion parameters
We'll assume for now that these parameters are given and fixed
geometry for a simple stereo system
Assume parallel optical axes, known camera parameters (i.e., calibrated cameras)
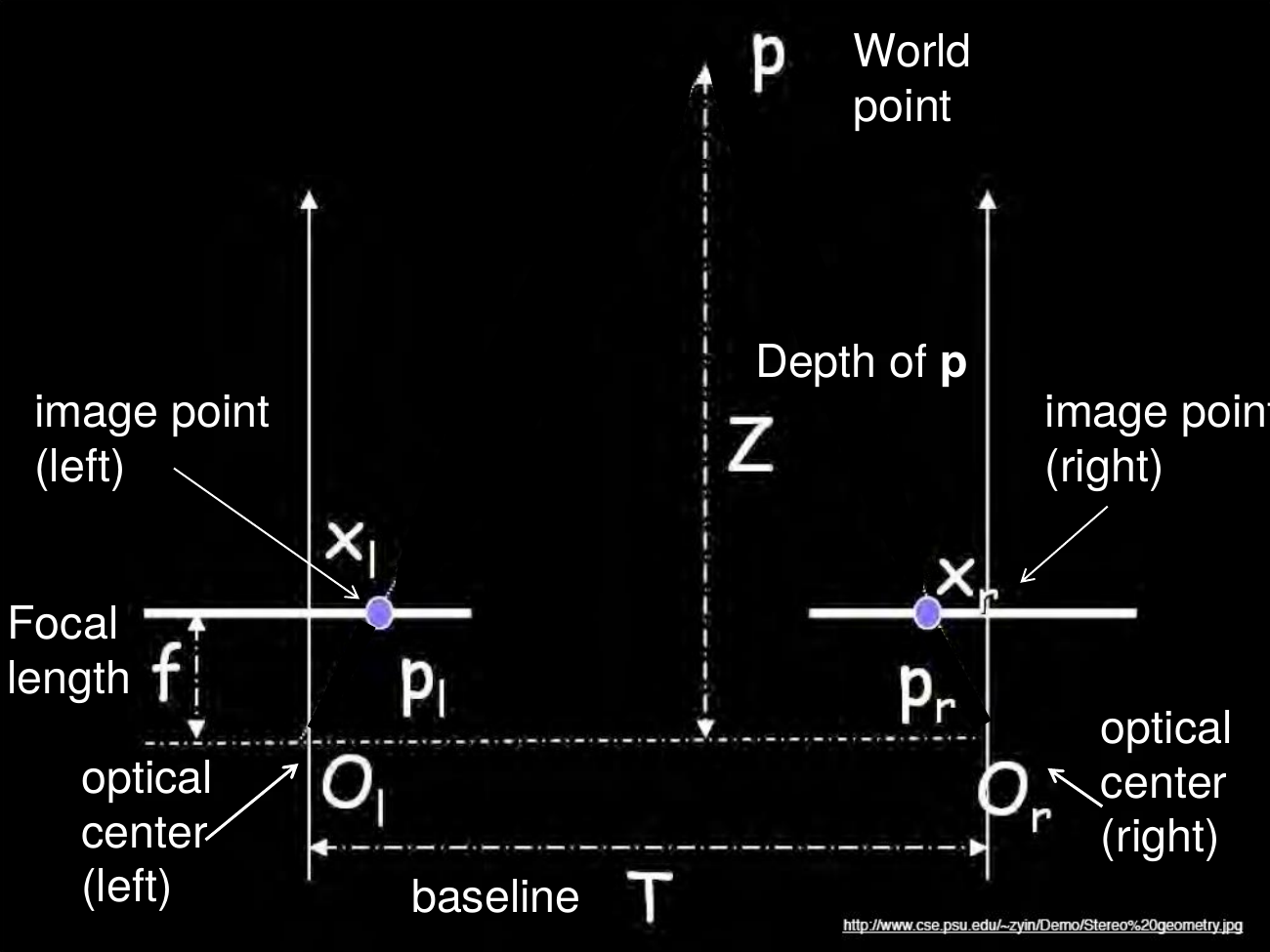
geometry for a simple stereo system
Assume parallel optical axes, known camera parameters (i.e., calibrated cameras)
What is expression for \(Z\)?
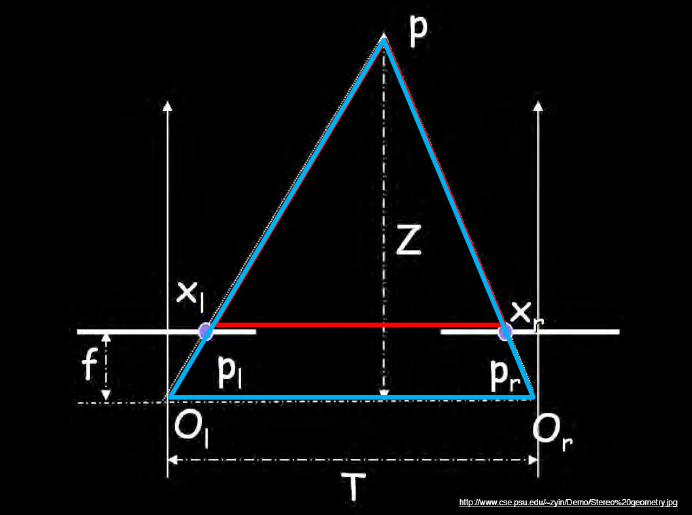 |
Similar triangles \((p_l, p, p_r)\) and \((o_l, p, o_r)\): \[\frac{T + x_l - x_r}{Z - f} = \frac{T}{Z}\] \[Z = f \frac{T}{x_r - x_l}\] Disparity: \(x_r-x_l\) |
depth from disparity
So if we could find the corresponding points in two images, we could estimate relative depth...



\[(x',y') = (x+D(x,y), y)\]
autostereograms
