Algorithm Analysis
COS 320 - Algorithm Design
Algorithm Analysis
Computational Tractability (2.1)
a strikingly modern thought
“As soon as an Analytic Engine exists, it will necessarily guide the future course of the science. Whenever any result is sought by its aid, the question will arise—By what course of calculations can these results be arrived at by the machine in the shortest time?
”
–Charles Babbage (1864)
 |
 |
models of computation: turing machines
Deterministic Turing Machine: simple and idealistic model
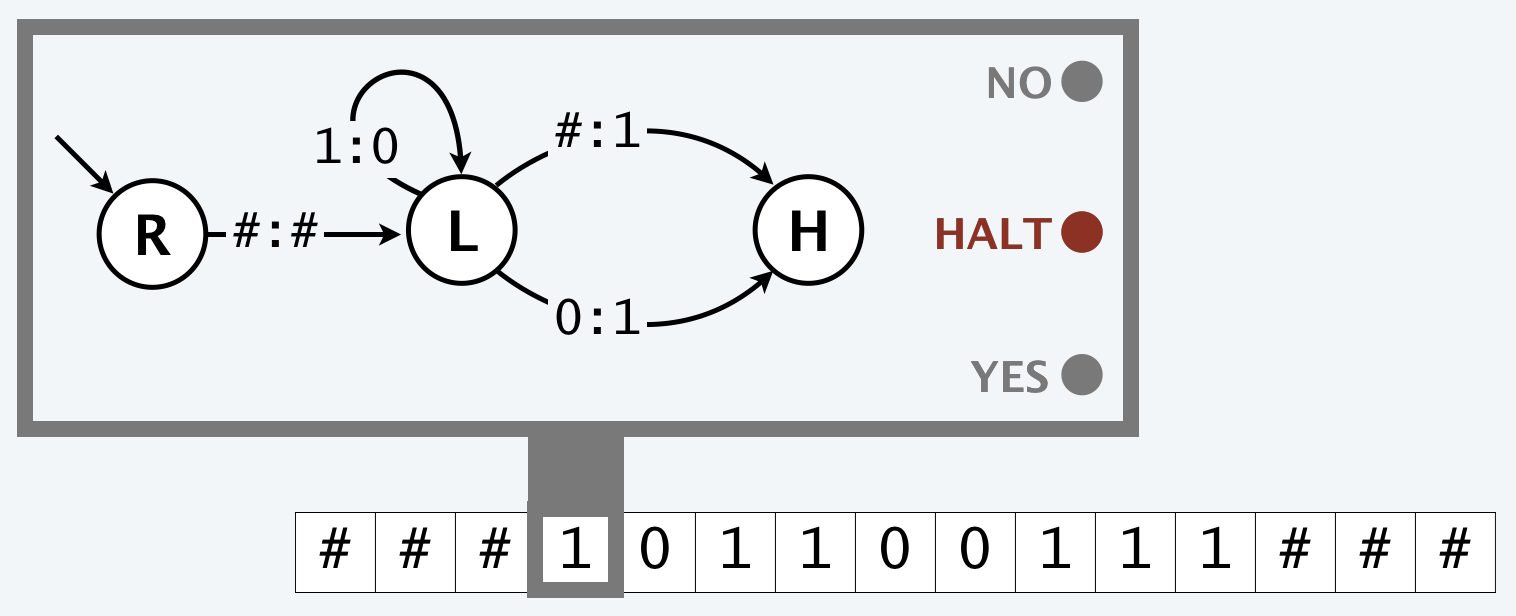
Running time: number of steps
Memory: number of tape cells utilized
Caveat: No random access of memory
- Single-tape TM requires \(\geq n^2\) steps to detect \(n\)-bit palindromes
- Easy to detect palindromes in \(\leq cn\) steps on a real computer
models of computation: word ram
Word RAM
- Each memory location and input/output cell stores a \(w\)-bit integer (assume \(w \geq \log_2 n\))
- Primitive operations: arithmetic/logic operations, read/write memory, array indexing, following a pointer, conditional branch, ... (constant-time C-style operations; \(w=64\))
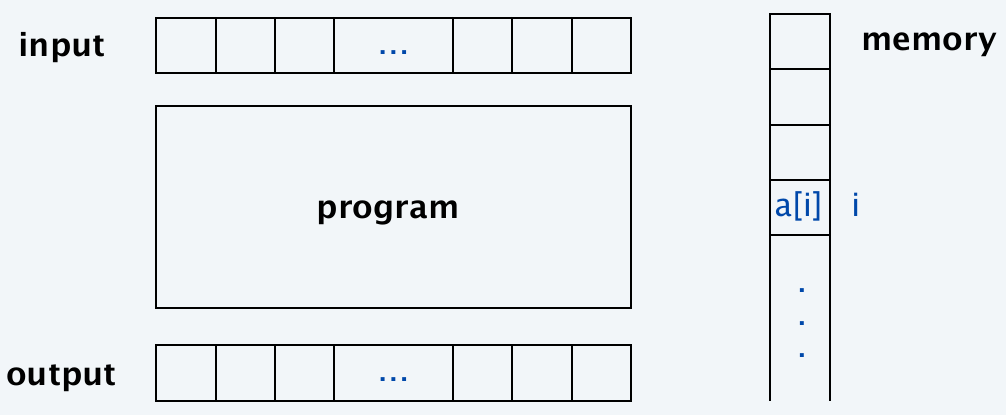
Running time: number of primitive operations
Memory: Number of memory cells utilized
Caveat: At times, need more refined model (e.g., multiply \(n\)-bit ints)
brute force
Brute Force: For many nontrivial problems, there is a natural brute-force search algorithm that checks every possible solution.
- Typically takes \(2^n\) steps (or worse) for inputs of size \(n\)
- Unacceptable in practice

Ex: Stable matching problem: test all \(n!\) perfect matchings for stability
polynomial running time
Desirable scaling property: When the input size doubles, the algorithm should slow down by at most some constant factor \(C\)
- Polynomial Time
-
An algorithm is poly-time if the above scaling property holds
There exist constants \(a > 0\) and \(b > 0\) such that, for every input of size \(n\), the running time of the algorithm is bounded above by \(a n^b\) primitive computational steps.
 |
 |
 |
 |
 |
 |
polynomial running time
We say that an algorithm is efficient if it has a polynomial running time
Theory: Definition is (relatively) insensitive to model of computation
Practice: It really works!
- The poly-time algorithms that people develop have both small constants and small exponents
- Breaking through the exponential barrier of brute force typically exposes some crucial structure of the problem
Exceptions: Some poly-time algorithms in the wild have galactic constants and/or huge exponents
Q. Which would you prefer:
- poly-time \(20 n^{120}\), or
- non-poly-time \(n^{1+0.02\ln n}\)?
worst-case analysis
Worst Case: running time guarantee for any input of size \(n\)
- Generally captures efficiency in practice
- Draconian view, but hard to find effective alternative
Exceptions: Some exponential-time algorithms are used widely in practice, because the worst-case instances don't arise.
 |
 |
 |
other types of analyses
Probabilistic: Expected running time of a randomized algorithm
- Ex: The expected number of compares to quicksort \(n\) elements is \(\sim 2n \ln n\)
Amortized: Worst-case running time for any sequence of \(n\) operations
- Ex: starting from an empty stack, any sequence of \(n\) push and pop operations takes \(O(n)\) primitive computational steps using a resizing array
Also: Average-case analysis, smoothed analysis, competitive analysis, ...
Algorithm Analysis
Asymptotic Order of Growth (2.2)
big O notation
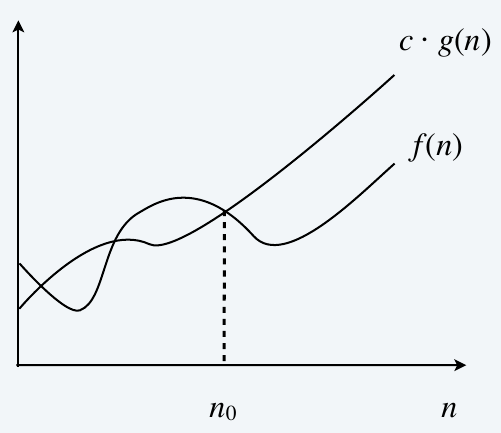
Upper Bounds: \(f(n)\) is \(O(g(n))\) if there exist constants \(c > 0\) and \(n_0 \geq 0\) such that \(0 \leq f(n) \leq c \cdot g(n)\) for all \(n \geq n_0\).
Ex: \(f(n) = 32 n^2 + 17 n + 1\)
- \(f(n)\) is \(O(n^2)\). (choose \(c=50\), \(n_0=1\))
- \(f(n)\) is neither \(O(n)\) nor \(O(n \log n)\)
Typical usage: Insertion sort makes \(O(n^2)\) compares to sort \(n\) elements.
Quiz: analysis of algorithms
Let \(f(n) = 3n^2 + 17n \log_2 n + 1000\).
Which of the following are true?
- \(f(n)\) is \(O(n^2)\).
- \(f(n)\) is \(O(n^3)\).
- Both A and B.
- Neither A nor B.
Big O notational abuses
One-way "equality": \(O(g(n))\) is a set of functions, but computer scientists often write \(f(n) = O(g(n))\) instead of \(f(n) \in O(g(n))\)
Ex: Consider \(g_1(n) = 5n^3\) and \(g_2(n) = 3n^2\).
- We have \(g_1(n) = O(n^3)\) and \(g_2(n) = O(n^3)\).
- But, do not conclude that \(g_1(n) = g_2(n)\)
Domain and Codomain: \(f\) and \(g\) are real-valued functions
- The domain is typically the natural numbers: \(\mathbb{N} \rightarrow \mathbb{R}\) (input size, recurrence relations)
- Sometimes we extend to the reals: \(\mathbb{R}_{\geq0} \rightarrow \mathbb{R}\) (plotting, limits, calculus)
- Or restrict to a subset
Bottom line: OK to abuse notation in this way; not OK to misuse it.
Big o notation: properties
| Reflexivity | \(f\) is \(O(f)\) |
| Constants | If \(f\) is \(O(g)\) and \(c > 0\), then \(c f\) is \(O(g)\) |
| Products | If \(f_1\) is \(O(g_1)\) and \(f_2\) is \(O(g_2)\), then \(f_1f_2\) is \(O(g_1g_2)\) (proof) |
| Sums | If \(f_1\) is \(O(g_1)\) and \(f_2\) is \(O(g_2)\), then \(f_1 + f_2\) is \(O(\max (g_1, g_2))\) (ignore lower-order terms) |
| Transitivity | If \(f\) is \(O(g)\) and \(g\) is \(O(h)\), then \(f\) is \(O(h)\). |
Examples:
- \(f(n) = 1000n\) is \(O(n)\)
- \(f(n) = 5n^3 + 3n^2 + n + 1234\) is \(O(n^3)\)
big omega notation
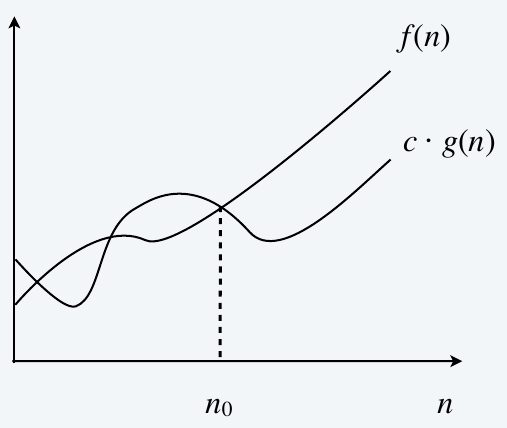
Lower Bounds: \(f(n)\) is \(\Omega(g(n))\) if there exists constants \(c > 0\) and \(n_0 \geq 0\) such that \(f(n) \geq c \cdot g(n) \geq 0\) for all \(n \geq n_0\).
Ex: \(f(n) = 32n^2 + 17n + 1\).
- \(f(n)\) is \(\Omega(n^2)\) (\(c=32\), \(n_0=1\))
- \(f(n)\) is also \(\Omega(n)\)
- \(f(n)\) is not \(\Omega(n^3)\)
Typical usage: Any compare-based sorting algorithm requires \(\Omega(n \log n)\) compares in the worst case.
Vacuous statement: Any compare-based sorting algorithm requires at least \(O(n \log n)\) compares in the worst case (upper bound (\(O\)) is lower bound ("at least")?)
quiz: analysis of algorithms
Which is an equivalent definition of big Omega notation?
Assume: \(n \in \mathbb{Z}\)
-
\(f(n)\) is \(\Omega(g(n))\) iff \(g(n)\) is \(O(f(n))\).
-
\(f(n)\) is \(\Omega(g(n))\) iff there exists constant \(c>0\) such that \(f(n) \geq c \cdot g(n) \geq 0\) for infinitely many \(n\).
-
Both A and B.
-
Neither A nor B.
big theta notation
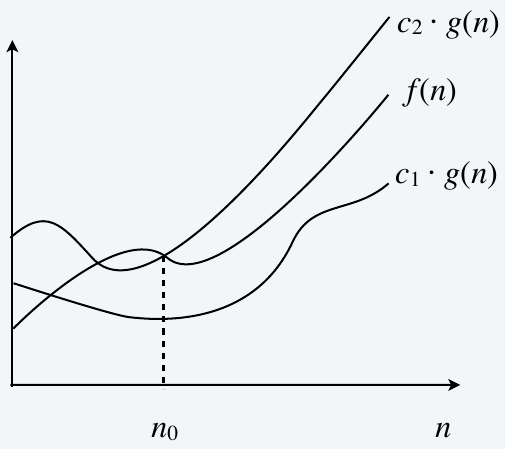
Tight bounds: \(f(n)\) is \(\Theta(g(n))\) if there exist constants \(c_1>0\), \(c_2>0\), and \(n_0\geq 0\) such that \(0 \leq c_1 g(n) \leq f(n) \leq c_2 g(n)\) for all \(n \geq n_0\).
Ex: \(f(n) = 32n^2 + 17n + 1\)
- \(f(n)\) is \(\Theta(n^2)\) (\(c_1 = 32\), \(c_2=50\), \(n_0=1\))
- \(f(n)\) is neither \(\Theta(n)\) nor \(\Theta(n^3)\)
- desmos
Typical usage: Mergesort makes \(\Theta(n \log n)\) compares to sort \(n\) elements (between \(\frac{1}{2} n \log_2 n\) and \(n \log_2 n\))
quiz: analysis of algorithms
Which is an equivalent definition of big Theta notation?
-
\(f(n)\) is \(\Theta(g(n))\) iff \(f(n)\) is both \(O(g(n))\) and \(\Omega(g(n))\).
-
\(f(n)\) is \(\Theta(g(n))\) iff \(\displaystyle\lim_{n\rightarrow\infty} \frac{f(n)}{g(n)} = c\) for some constant \(0 < c < \infty\).
-
Both A and B.
-
Neither A nor B.
asymptotic bounds and limits
Proposition: If \(\displaystyle\lim_{n\rightarrow\infty} \frac{f(n)}{g(n)} = c\) for some constant \(0 < c < \infty\) then \(f(n)\) is \(\Theta(g(n))\).
Pf:
- By definition of the limit, there exists \(n_0\) such that for all \(n \geq n_0\) \[ c - \epsilon \leq \frac{f(n)}{g(n)} \leq c + \epsilon \]
- Choose \(\epsilon = \frac{1}{2} c > 0\)
- Multiplying by \(g(n)\) yields \(\frac{1}{2} c \cdot g(n) \leq f(n) \leq \frac{3}{2}c \cdot g(n)\) for all \(n \geq n_0\).
- Thus, \(f(n)\) is \(\Theta(g(n))\) by definition, with \(c_1 = \frac{1}{2}c\) and \(c_2 = \frac{3}{2}c\).
asymptotic bounds and limits
Propositions:
-
If \(\displaystyle\lim_{n\rightarrow\infty} \frac{f(n)}{g(n)} = 0\), then \(f(n)\) is \(O(g(n))\) but not \(\Omega(g(n))\)
-
If \(\displaystyle\lim_{n\rightarrow\infty} \frac{f(n)}{g(n)} = \infty\), then \(f(n)\) is \(\Omega(g(n))\) but not \(O(g(n))\)
asymptotic bounds for some common fns
Polynomials: Let \(f(n) = a_0 + a_1n + \ldots + a_dn^d\) with \(a_d>0\). Then, \(f(n)\) is \(\Theta(n^d)\).
Pf:
\[ \lim_{n\rightarrow\infty} \frac{a_0 + a_1n + \ldots + a_dn^d}{n^d} = a_d > 0 \]
Logarithms: \(\log_a n\) is \(\Theta(\log_b n)\) for every \(a>1\) and every \(b > 1\). (no need to specify base assuming it is a constant)
Pf:
\[ \frac{\log_a n}{\log_b n} = \frac{1}{\log_b a}\]
asymptotic bounds for some common fns
Logarithms and Polynomials: \(\log_a n\) is \(O(n^d)\) for every \(a > 0\) and every \(d > 0\)
Pf:
\[ \lim_{n\rightarrow\infty} \frac{\log_a n}{n^d} = 0 \]
Exponentials and Polynomials: \(n^d\) is \(O(r^n)\) for every \(r>1\) and every \(d>0\).
Pf:
\[ \lim_{n\rightarrow\infty} \frac{n^d}{r^n} = 0 \]
asymptotic bounds for some common fns
Factorials: \(n!\) is \(2^{\Theta(n \log n)}\).
\[ n! \sim \sqrt{2\pi n} \left(\frac{n}{e}\right)^n \]
Big O notation with multiple variables
Upper Bounds: \(f(m,n)\) is \(O(g(m,n))\) if there exist constants \(c>0\), \(m_0\geq0\), and \(n_0\geq 0\) such that \(0 \leq f(m,n) \leq c \cdot g(m,n)\) for all \(n \geq n_0\) and \(m \geq m_0\).
Ex: \(f(m,n) = 32mn^2 + 17mn + 32n^3\)
- \(f(m,n)\) is both \(O(mn^2 + n^3)\) and \(O(mn^3)\).
- \(f(m,n)\) is neither \(O(n^3)\) nor \(O(mn^2)\)
- \(f(m,n)\) is \(O(n^3)\) as long a precondition to the problem implies \(m \leq n\)
Typical usage: Breadth-first search takes \(O(m+n)\) time to find a shortest path from \(s\) to \(t\) in a digraph with \(n\) nodes and \(m\) edges.
Algorithm Analysis
Stable Matching using Lists and Arrays (2.3)
efficient implementation
Goal: Implement Gale-Shapley to run in \(O(n^2)\) time
// Gale-Shapley (preference lists for hospitals and students)
Initialize M to empty matching
While some hospital h is unmatched and hasn't proposed to every student:
s <- first student on h's list to whom h has not yet proposed
If s is unmatched
Add h-s to matching M
Else If s prefers h to current partner h'
Replace h'-s with h-s in matching M
Else
s rejects h
Return stable matching M
efficient implementation
Goal: Implement Gale-Shapley to run in \(O(n^2)\) time
Representing hospitals and students: Index hospitals and students 1, ..., n
Representing the matching:
- Maintain two arrays
students[h]andhospitals[s]- initially
students[h]=0for allhandhospitals[s]=0for allsto designate that all hospitals and students are unmatched - if \(h\) matched to \(s\), then
students[h] = sandhospitals[s] = h
- initially
- ...
Key: Can add/remove a pair from matching in \(O(1)\) time
efficient implementation
Goal: Implement Gale-Shapley to run in \(O(n^2)\) time
Representing the matching:
- Maintain two arrays
students[h]andhospitals[s]- ...
- Maintain set of unmatched hospitals in a queue or stack
- initially all hospitals in queue (or stack)
Key: Can find an unmatched hospital in \(O(1)\) time
data representation: making a proposal
Hospital makes a proposal
- Key operation: find hospital's next favorite student
- For each hospital: maintain list of students, ordered by preference
- For each hospital: maintain pointer to student for next proposal
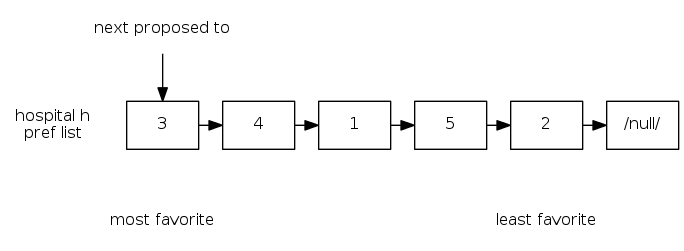
Key: Can make a proposal in \(O(1)\) time.
data representation: accepting/rejecting
Student accepts/rejects a proposal
- Does student \(s\) prefer hospital \(h\) to hospital \(h'\)?
- For each student, create inverse of preference list of hospitals.
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | |
|---|---|---|---|---|---|---|---|---|
pref[]: |
8 | 3 | 7 | 1 | 4 | 5 | 6 | 2 |
for i = 1 to n
inverse[pref[i]] = i
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
inverse[] |
4th | 8th | 2nd | 5th | 6th | 7th | 3rd | 1st |
Key: After \(\Theta(n^2)\) preprocessing time (to create the \(n\) ranking arrays, each of length \(n\)), it takes \(O(1)\) time to accept/reject a proposal.
stable matching: summary
Theorem: We can implement Gale-Shapley to run in \(O(n^2)\) time.
Pf:
- \(\Theta(n^2)\) preprocessing time to create the \(n\) ranking arrays.
- There are \(O(n^2)\) proposals; processing each proposal takes \(O(1)\) time. ∎
Theorem: In the worst case, any algorithm to find a stable matching must query the hospital's preference list \(\Omega(n^2)\) times.
Algorithm Analysis
Survey of common running times (2.4)
Constant time
Constant time: Running time is \(O(1)\) (bounded by a constant, which does not depend on input size \(n\))
Examples:
- Conditional branch
- Arithmetic/logic operation
- Declare/initialize a variable
- Follow a link in a linked list
- Access element \(i\) in an array
- Compare/exchange two elements in an array
- ...
Linear time
Linear time: Running time is \(O(n)\)
Merge two sorted lists: Combine two sorted linked lists \(A = a_1, a_2, \ldots, a_n\) and \(B = b_1, b_2, \ldots, b_n\) into a sorted whole.
\(O(n)\) algorithm: Merge in Mergesort.
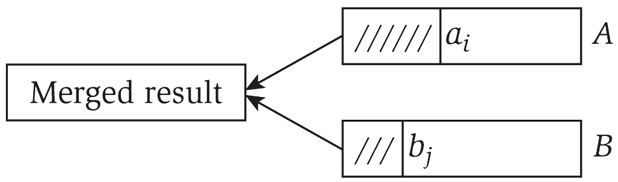
i <- 1; j <- 1.
While both lists are nonempty:
If a[i] <= b[j]
Append a[i] to output list and increment i
Else
Append b[j] to output list and increment j
Append remaining elements from nonempty list to output list
group: target sum
Target-Sum: Given a sorted array of \(n\) distinct integers and an integer \(T\), find two that sum exactly \(T\).
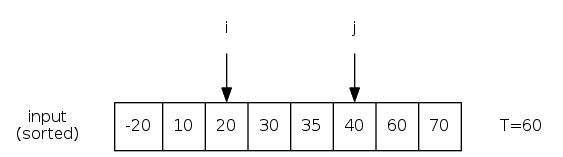
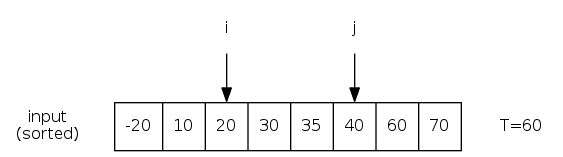
\(O(n^2)\) algorithm: Try all pairs
\(O(n)\) algorithm: Exploit sorted order
- Start pointers on left \(i\) and right \(j\) side
- If \(i\)-\(j\) pair sum to \(T\), found!
- Otherwise, move pointers toward middle depending on sum:
- If \(<T\), move \(i\) right (need larger sum)
- If \(>T\), move \(j\) left (need smaller sum)
Invariant: no element left of \(i\) or right of \(j\) sums to \(T\)
logarithmic time
Logarithmic time: Running time is \(O(\log n)\)
Search in a sorted array: Given a sorted array \(A\) of \(n\) numbers, is a given number \(x\) in the array?
\(O(\log n)\) algorithm: Binary search
- Invariant: If \(x\) is in the array, then \(x\) is in \(A[lo..hi]\) (remaining elements)
- After \(k\) iterations of loop, \[ (hi-lo+1) \leq n/2^k \quad\Rightarrow\quad k \leq 1 + \log_2 n \]
group: Search in a sorted rotated array
Search-in-Sorted-Rotated-Array: Given a rotated sorted array of \(n\) distinct integers and an element \(x\), determine if \(x\) is in the array.
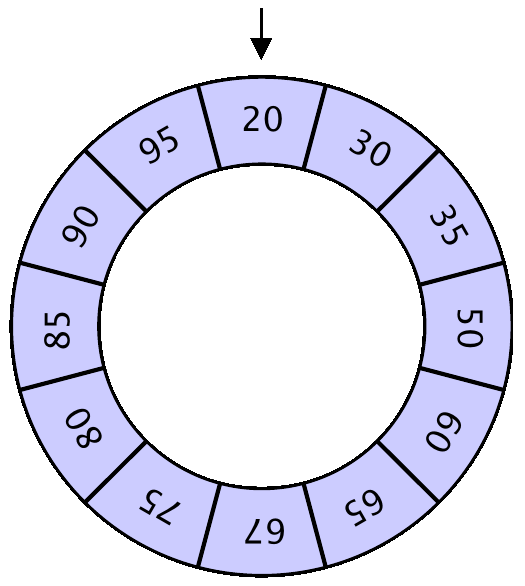
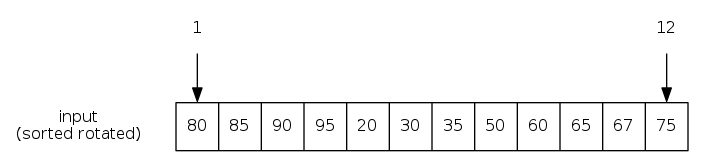
\(O(\log n)\) algorithm
- Find index \(k\) of smallest element
- Binary search for \(x\) in either
A[1 .. k-1]orA[k .. n]
// find index of smallest element
lo <- 1; hi <- n.
If (A[lo] <= A[hi]) Return 0 // sorted
While (lo + 2 <= hi): // at least 3 elements
mid <- floor((lo + hi) / 2) // loop invariant: A[lo] > A[hi]
If (A[mid] < A[hi]) hi <- mid
Else If (A[mid] > A[hi]) lo <- mid
Return hi
linearithmic time
Linearithmic time: Running time is \(O(n \log n)\)
Sorting: Given an array of \(n\) elements, rearrange them in ascending order.
\(O(n \log n)\) algorithm: Mergesort

group: largest empty interval
Largest-Empty-Interval: Given \(n\) timestamps \(x_1, \ldots, x_n\) on which copies of a file arrive at a server, what is largest interval when no copies of file arrive?
quadratic time
Quadratic time: Running time is \(O(n^2)\)
Closest pair of points: Given a list of \(n\) points in the plane \((x_1,y_1), \ldots, (x_n,y_n)\), find the pair that is closest to each other.
\(O(n^2)\) algorithm: Enumerate all pairs of points.
min <- infty
For i = 1 to n
For j = i+1 to n
d <- (x[i] - x[j])^2 + (y[i] - y[j])^2
If d < min
min <- d
Remark on Closest Pair: \(\Omega(n^2)\) seems inevitable, but this is just an illusion (see section 5.4 Finding the Closest Pair of Points)
cubic time
Cubic time: Running time is \(O(n^3)\)
3-Sum: Given an array of \(n\) distinct ints, find three that sum to 0
\(O(n^3)\) algorithm: Enumerate all triples.
For i = 1 to n
For j = i+1 to n
For k = j+1 to n
If a[i] + a[j] + a[k] = 0
Return (a[i], a[j], a[k])
Remark on 3-Sum: \(\Omega(n^3)\) seems inevitable, but \(O(n^2)\) is not hard.
group: 3-sum
3-Sum: Given an array of \(n\) distinct ints, find three that sum to 0
polynomial time
Polynomial time: Running time is \(O(n^k)\) for some constant \(k > 0\)
Independent set of size \(k\): Given a graph, find \(k\) nodes (\(k\) is constant) such that no two are joined by an edge.
\(O(n^k)\) algorithm: Enumerate all subsets of \(k\) nodes.
Foreach subset S of k nodes: // O(n^k/k!) reps
Check whether S is an independent set. // k^2
If S is an independent set
Return S
- Check whether \(S\) is an ind. set of size \(k\) takes \(O(k^2)\) time
- Number of \(k\)-element subsets
- \(\binom{n}{k} = \frac{n(n-1)(n-2)\cdots(n-k+1)}{k(k-1)(k-2)\cdots 1} \leq \frac{n^k}{k!}\) is \(O(\frac{n^k}{k!})\)
- Reminder \(k\) is constant and \(O(k^2 n^k / k!) \in O(n^k)\)
- poly-time! but not practical when \(k\) is large (ex: \(k=17\))
exponential time
Exponential time: Running time is \(O(2^{n^k})\) for some constant \(k>0\)
Independent set: Given a graph, find independent set of max cardinality
\(O(n^2 2^n)\) algorithm: Enumerate all subsets
S* <- empty // constant
Foreach subset S of nodes: // 2^n reps
Check whether S is an independent set // n^2
If S is an independent set AND |S| > |S*|
S* <- S
Return S*
quiz: Analysis of Algorithms
Which is an equivalent definition of exponential time?
-
\(O(2^n)\)
-
\(O(2^{cn})\) for some constant \(c > 0\)
-
Both A and B
-
Neither A nor B
Appendix: Big O Notation: properties #
Products
- If \(f_1\) is \(O(g_1)\) and \(f_2\) is \(O(g_2)\), then \(f_1f_2\) is \(O(g_1g_2)\).
Pf:
- \(\exists c_1 > 0\) and \(n_1 \geq 0\) such that \(0 \leq f_1(n) \leq c_1 \cdot g_1(n)\) for all \(n \geq n_1\)
- \(\exists c_2 > 0\) and \(n_2 \geq 0\) such that \(0 \leq f_2(n) \leq c_2 \cdot g_2(n)\) for all \(n \geq n_2\)
- Then, \(0 \leq f_1(n) \cdot f_2(n) \leq c_1 \cdot c_2 \cdot g_1(n) \cdot g_2(n)\) for all \(n \leq \max \{n_1, n_2\}\).